

I’ve been getting some questions regarding o1 from friends.
Below were my responses covering its IOI scores, reasoning capability, scaling, and potential implications for codegen!
Email #1
I haven't looked too deeply into the code-gen space except for a conversation here and there – I feel like it's an area that someone with coding experience can speak much better to.
But I have been thinking of how the o1 release will impact these companies. o1's MATH and MMLU scores are pretty much what I expected. But their programming score was extremely impressive and showed a massive jump. That caught me by surprise.
I did a quick analysis comparing o1's IOI score to that of humans. It's interesting how it crushes humans on the Hieroglyph problem (though still far from perfect) but gets destroyed on Mosaic. Typically in the case of math, LLMs do well on the easy problems but not the medium/hard ones. I'd be interested in seeing a granular study that analyzes the coding problems that LLMs are good at, similar to how we know that LLMs are good at algebra and number theory problems but not combinatorics. That way, mediocre engineers would know where they really need help and truly get to gold medal level.
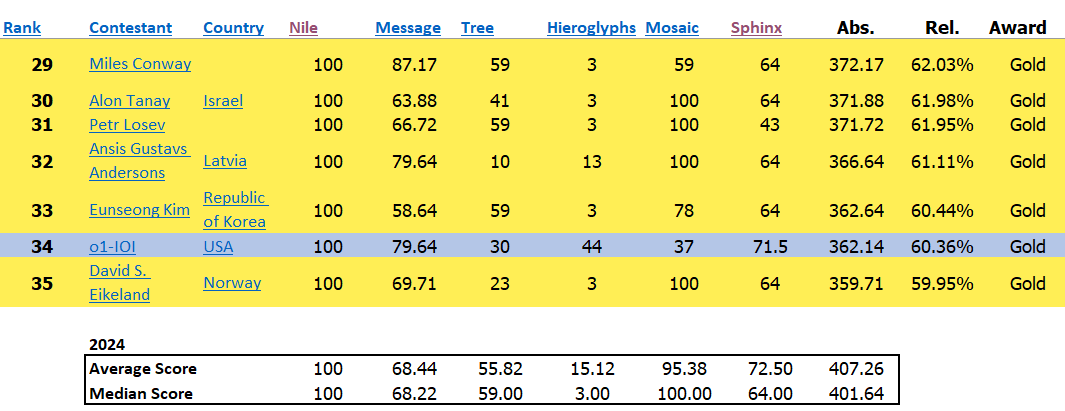
In line with this, I find the system around o1-IOI very interesting.
For each problem, our system sampled many candidate submissions and submitted 50 of them based on a test-time selection strategy. Submissions were selected based on performance on the IOI public test cases, model-generated test cases, and a learned scoring function. If we had instead submitted at random, we would have only scored 156 points on average, suggesting that this strategy was worth nearly 60 points under competition constraints.
Implementing an automated way of doing this will be the key to success for the next generation of code gens in my opinion. I remember we briefly chatted about the importance of having different tools for these code-gen models. I think more people will implement a system around it. We already see Morph (the Khosla one haha) going after this in several ways. Neurosymbolic AI is really making a comeback!
Email #2
Hey [ ],
I got your text. Thought I'd respond here since it's a bit easier for me to type things.
o1 is impressive but it's hard to do a 1:1 comparison. o1 was tested on AIME qualification test and not on IMO exams, which was what deepmind's alphaproof was tested on. My initial take is that they likely tried but fell short of the state of the art, hence not talking about it much. With that said, there's always a chance that it will get better and eventually beat it. o1's MATH score is impressive though. I think it's definitely SOTA for standalone models without API calls.
One thing to note is that o1 still doesn't eliminate hallucinations. Chain of thought, MCTS, tree of thought, and other attempts to force models to reason are definitely promising routes, but hallucinations are still a problem (albeit could be less than just regular prompting). Deepmind's system is specifically designed to eliminate this. That's why they have the theorem prover to help verify results.
If anything, Deepmind could very well leverage the techniques used by o1. It feels like a fairly simple prompting strategy with some type of a reward model attached.
Assuming my above statements and assumptions are correct, the key risk here is how open the end customers are with the potential friction of incorporating the reasoning system of deepmind vs. openai. Openai's feels fairly easy to use off the shelf, whereas the tech of deepmind will need more tailoring and customization.
Final thing to point out is how much of this improvement is from scaling law. Models get better with scale. GPT-4 was supposedly a 1.7T parameter MOE model. I'm guessing o1 is using the same model or even a bigger one. The question remains how performant a model is on a per flop basis. Even if o1 is beating benchmark numbers, it won't be that impressive if another company can do the same thing with the same amount of training compute available. This is an area of research that "pure" researchers are going after. It narrows down where the performance is coming from besides straight up scaling.
hope that helps!